
Le besoin en information sur les entreprises est croissant. Que ce soit pour évaluer la solvabilité ou la fiabilité de clients et de fournisseurs avant d’entamer une relation commerciale, se conformer à la loi Sapin 2, mener un audit d’acquisition..
L’INPI propose différentes solutions pour accéder aux informations juridiques et financières publiées par les entreprises : portail, FTP et API.
L’objet de cet article est de fournir quelques clefs pour démontrer tout l’intérêt d’utiliser un script Python pour automatiser la collecte en masse de la documentation juridique et financières des entreprises à l’aide de requêtes sur l’API (Application Programming Interface ou interface de programmation applicative) de l’INPI.
Pour fonctionner le script Python nécessite des identifiants de connexion à l’API INPI stockés dans un fichier texte nommé Identifiants_API_INPI.txt et une liste de numéros SIREN enregistrés dans un fichier intitulé SIREN à interroger.txt.

Pour obtenir ses identifiants, il faut au préalable s’inscrire sur le site de l’INPI : https://data.inpi.fr/login.
Une fois l’inscription réalisée, se rendre dans l’espace personnel :
Puis cliquer sur Mes accès APIS / SFTP puis Accès APIs RNE :
Ensuite, cliquer sur le bouton :
 Enfin, décrire le projet dans la zone de saisie et cocher les API voulues (Actes et Comptes annuels).
Enfin, décrire le projet dans la zone de saisie et cocher les API voulues (Actes et Comptes annuels).
Le script Python à rédiger doit reprendre les étapes décrites ci-après :
1ère étape : lecture des identifiants de connexion à l’API
Dans notre exemple, les identifiants sont lus à partir d’un fichier et stockés dans les variables username et password.
# Lecture des identifiants depuis un fichier
def lecture_des_identifiants(fichier_ID_API_INPI):
try:
with open(fichier_ID_API_INPI, 'r') as file:
lignes = file.readlines()
if len(lignes) >= 2:
username = lignes[0].strip()
password = lignes[1].strip()
return username, password
else:
raise Exception("Le fichier ne contient pas les informations d'identification nécessaires.")
except Exception as e:
raise Exception(f"Erreur lors de la lecture du fichier d'identifiants : {str(e)}")
2ème étape : lecture de la liste des numéros SIREN à interroger
La liste des SIREN à interroger est stockée dans un fichier texte (un SIREN par ligne). Le code suivant en assure la lecture (open) et le stockage (liste_siren = [line.strip() for line in file]) dans la variable liste_siren.
La variable nb_siren dénombre les SIREN à interroger.
# Lecture des SIREN à interroger à partir d'un fichier
def lecture_liste_siren(fichier_siren):
liste_siren = []
with open(fichier_siren, 'r') as file:
liste_siren = [line.strip() for line in file]
with open(fichier_siren, 'r') as file:
nb_siren = len(file.readlines())
return liste_siren, nb_siren
3ème étape : connexion à l’API
Avant d’interroger les fiches SIREN, il est nécessaire d’obtenir un token. Ce dernier est obtenu après communication des identifiants (username et password) au registre national des entreprises géré par l’INPI (url = “https://registre-national-entreprises.inpi.fr/api/sso/login”).
# Connexion API et obtention token
def collecte_token(username, password):
url = "https://registre-national-entreprises.inpi.fr/api/sso/login"
headers = {"Content-Type": "application/json"}
data = {"username": username, "password": password}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200:
return response.json()["token"]
else:
raise Exception(f"Échec de l'authentification. Code d'erreur : {response.status_code}")
La variable response lit le statut du serveur. Par exemple, si l’authentification aboutit, cette variable égale à 200 (statut OK). Les principaux statuts (ou codes d’erreur) sont listés plus loin.
4ème étape : collecte de la liste des documents disponibles
Une requête est envoyée à l’API (url = f”https://registre-national-entreprises.inpi.fr/api/companies/{siren}/attachments”) incluant le token (headers = {“Authorization”: f”Bearer {token}”}).
Si la requête aboutit (if response.status_code == 200), l’API retourne la liste des documents (documents = response.json()) disponibles au téléchargement.
Ensuite, la boucle for document_type in [“bilans”, “actes”] passe en revue tous les documents financiers et juridiques. Le nom du fichier à télécharger (variable nom_fichier) est calculé fonction de la nature du document (match document_type).
# Liste les documents et lance leur téléchargement
def telecharge_documents(siren, token, dossier_siren):
# Paramètres requête API
url = f"https://registre-national-entreprises.inpi.fr/api/companies/{siren}/attachments"
headers = {"Authorization": f"Bearer {token}"}
# Interroge le serveur INPI
response = requests.get(url, headers=headers)
# Statut API ok...
if response.status_code == 200:
# Collecte liste des documents disponibles au téléchargement
documents = response.json()
# Passe en revue tous les documents disponibles pour éventuel téléchargement
for document_type in ["bilans", "actes"]:
for document in documents.get(document_type, []):
document_id = document["id"]
document_date_depot = document["dateDepot"]
match document_type:
case "bilans":
document_type_bilan = document["typeBilan"]
document_date_cloture = document["dateCloture"]
nom_fichier = f"{document_type}_{siren}_{document_date_cloture}_{document_type_bilan}_{document_date_depot}_{document_id}.pdf"
telecharge_document(document_type, document_id, nom_fichier, siren, token, dossier_siren)
case "actes":
type_acte = "type acte inconnu"
if "typeRdd" in document and document["typeRdd"]:
type_acte = document["typeRdd"][0]["typeActe"]
nom_fichier = f"{document_type}_{siren}_{type_acte}_{document_date_depot}_{document_id}.pdf"
telecharge_document(document_type, document_id, nom_fichier, siren, token, dossier_siren)
case _:
print(f"Type de document non géré : {document_type}")
# ... ou Statut API = erreur
else:
raise Exception(f"Échec de la récupération des documents. Code d'erreur : {response.status_code}")
Ceci fait, le programme appelle la fonction telecharge_document(document_type, document_id, nom_fichier, siren, token, dossier_siren) afin de lancer le téléchargement du document :
# Télécharge un document (bilan, bilan saisi, ou acte) à partir de son identifiant
def telecharge_document(document_type, document_id, nom_fichier, siren, token, dossier_siren):
# Paramètres requête API
url = f"https://registre-national-entreprises.inpi.fr/api/{document_type}/{document_id}/download"
headers = {"Authorization": f"Bearer {token}"}
try:
# Affiche le nom du fichier en cours
message=f"\tDocument {nom_fichier} : "
message_complet=message
print(message,end="")
# Vérifie si le fichier existe déjà
# Si existe déjà : affiche le message "Le document existe déjà. Téléchargement abandonné..."...
chemin_fichier = os.path.join(dossier_siren, nom_fichier)
if fichier_existe(chemin_fichier):
message="Le document existe déjà. Téléchargement abandonné..."
message_complet=message_complet + message
print(message)
# ... sinon interrogation de L'API
else:
# Interroge le serveur INPI
response = requests.get(url, headers=headers)
# Statut API ok
if response.status_code == 200:
# Sauvegarde le contenu dans le dossier correspondant au SIREN
with open(chemin_fichier, "wb") as pdf_file:
pdf_file.write(response.content)
message="Le document est téléchargé."
message_complet=message_complet + message
print(message)
elif response.status_code == 404:
message="Le document n'a pas été trouvé."
message_complet=message_complet + message
print(message)
else:
message=f"Échec du téléchargement du document. Code d'erreur : {response.status_code}"
message_complet=message_complet + message
raise Exception(message)
journalisation_message(siren, message_complet, dossier_siren)
except Exception as e:
message=f"Une exception s'est produite lors du téléchargement du document : {str(e)}"
message_complet=message_complet + message
print(message)
journalisation_message(siren, message_complet, dossier_siren)
Le téléchargement passe, une fois encore, par l’interrogation du serveur (avec authentification). Chaque réponse du serveur est journalisée dans un fichier texte enregistré dans le même dossier (\{siren}) que les documents téléchargés afin de pouvoir vérifier ultérieurement l’exhaustivité des téléchargements.
Les documents déjà téléchargés (if fichier_existe(chemin_fichier)) ne sont pas téléchargés une nouvelle fois.
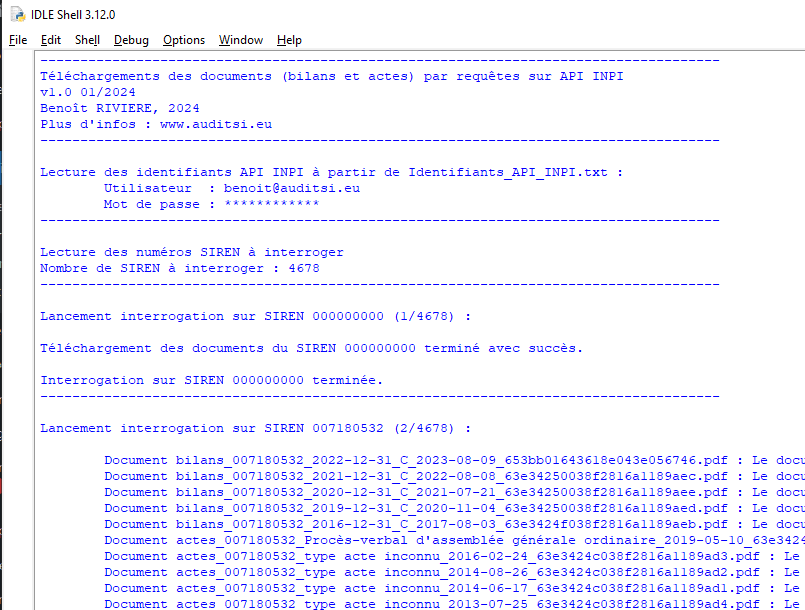
Exemple de contenu d’un dossier SIREN à l’issue de la boucle de téléchargement :
Fonction de journalisation des événements de téléchargement :
# Journalisation des messages
def journalisation_message(siren, message, dossier_siren):
nom_fichier_journalisation = f"Journalisation_API_INPI_{siren}.txt"
chemin_journalisation = os.path.join(dossier_siren, nom_fichier_journalisation)
# Test existence du fichier de journalisation
fichier_existe = os.path.exists(chemin_journalisation)
# Ouverture fichier en mode "a" (ajout) s'il existe, sinon création et ouverture en mode "w" (écriture)
with open(chemin_journalisation, "a" if fichier_existe else "w", encoding="utf-8") as journal_file:
journal_file.write(message + "\n")
Exemple de fichier de journalisation :
Liste des codes d’erreur (statuts) de l’API :

A noter : les transferts de données depuis l’API de l’INPI sont limités par des quotas quotidiens : 10 000 requêtes et 10 Go.
___
Pour approfondir le sujet : autres API utiles avec des exemples de codes VBA :
- Obtenir les distances et temps de parcours d’un trajet Google Maps
- Automatiser le téléchargement en masse des avis de situation SIRENE (avec l’API de l’INSEE)
- Obtenir les informations juridiques d’une société à l’aide de l’API de Pappers.fr
Exemple de requêtes web : Automatiser la lecture des données boursières Yahoo Finance

documentation-technique-API_comptes_annuels-v1.3.pdf
Version: 1.3
Derniers articles parBenoît RIVIERE (voir tous)
- Clôture comptable : optimiser l’existant pour mieux automatiser demain - dimanche 19 juillet 2026
- Quand un simple “œ” entraîne le rejet d’une liasse fiscale - mercredi 13 mai 2026
- Affiner le cadrage de la TVA avec ANA-FEC 2 - samedi 28 février 2026
- Comprendre l’hameçonnage en 30 secondes - samedi 21 février 2026
- Révision des comptes : justifier rapidement un compte non lettré avec Excel - dimanche 8 février 2026
Bonjour,
Je voulais savoir si je devais ajouter des variables telles que :
fichier_ID_API_INPI = os.path.join(dossier_travail, “Identifiant_API_INPI.txt”)
fichier_siren = os.path.join(dossier_travail, “SIREN à interroger.txt”)
Par ailleurs j’ai une erreur dans le code à ce niveau :
# Vérifie si le fichier existe déjà
# Si existe déjà : affiche le message “Le document existe déjà. Téléchargement abandonné…”…
chemin_fichier = os.path.join(dossier_siren, nom_fichier)
if fichier_existe(chemin_fichier):
=> fichier_existe en souligné d’une vague.
La fonction n’existe pas.
Merci d’avance pour votre aide.
Bien cordialement,
Pierrick COURTIN
Bonsoir,
Le but de cet article n’était pas de fournir clef en main un outil tout fait (comme je l’ai fait avec le FEC augmenté : https://www.auditsi.eu/?p=12196) mais d’évoquer une piste de réflexion sur l’intérêt et l’usage des API.
Le développement de ces outils est un investissement et je ne donne pas tous mes outils.
Pour tester l’existence d’un fichier, il faut utiliser la fonction os.path.isfile(nom_fichier) (cf exemple : https://www.auditsi.eu/?p=12196). J’ai créé une fonction fichier_existe mais cela n’est pas obligatoire.
Pour les fichier identifiants et SIRENE, vous devez bien entendu les ouvrir et en lire le contenu avant de lancer les traitements.
Bien cordialement,
B. RIVIERE
Bonjour,
Je me régale toujours autant en lisant vos articles. Il est vrai que le besoin d’informations sur les entreprises ne cesse d’augmenter. A cet effet, je me demandais si d’autres pays de l’UE et UK mettent à disposition ces informations à travers des API comme celui de la base SIRENE de l’INSEE ?
J’ai interrogé ChatGPT et COPILOT à ce sujet mais toutes les réponses que j’ai obtenues sont fausses voire inexploitables.
Auriez-vous quelques pistes à partager à ce sujet ?
Bonjour,
Merci pour votre message.
Non, je n’ai pas creusé ce sujet. Dans cet article (https://www.auditsi.eu/?p=9278), j’avais donné quelques sites européens qui fournissaient de l’information légale sur des entreprises locales. Mais point d’API. Il faudrait réactualiser le sujet.
Idéalement, il faudrait un site européen qui centralise l’information à l’échelle du continent à l’image de VIES (Commission Européenne) pour les numéros de TVA (https://www.auditsi.eu/?p=6739)… et cerise sur le gâteau avec une API avec des quotas de téléchargement assez élevés… Noël avant l’heure, quoi ;-).
Cordialement,
B. RIVIERE
Bonjour,
De mon cotés je privilégiais une approche systèmatique (tél. par annéee) en utiliant leur serveur SFTP dont la doc fait aussi état de ces quotats: “A noter : les transferts de données depuis l’API de l’INPI sont limités par des quotas quotidiens : 10 000 requêtes et 10 Go.”, mais j’ai plutot constaté une en pratique limite dure à 4168 fichiers par jours sur le serveurs et assez aléatoire sur l’api.
Je crois qu’ils sont assailis par les bots US et bloquent parfois les IP pendant une semaine.
Juste au cas où certains autres se posent les meme interrogations: pour on se fait sortir à moin sde 10k query et 10Go de download. Aussi le multi requetes (parallele) vous fait sortir en 20 minutes, filezilla, ok pour explorer mais pas pour télécharger (ça tourne en rond)
Bonjour,
Merci pour votre retour d’expérience.