
L’analyse de données comptables contenues dans un Fichier des Ecritures Comptables (FEC) est une pratique de plus en plus commune. Dans ce cadre, le langage Python est un formidable outil parfaitement adapté pour nettoyer et manipuler les données.
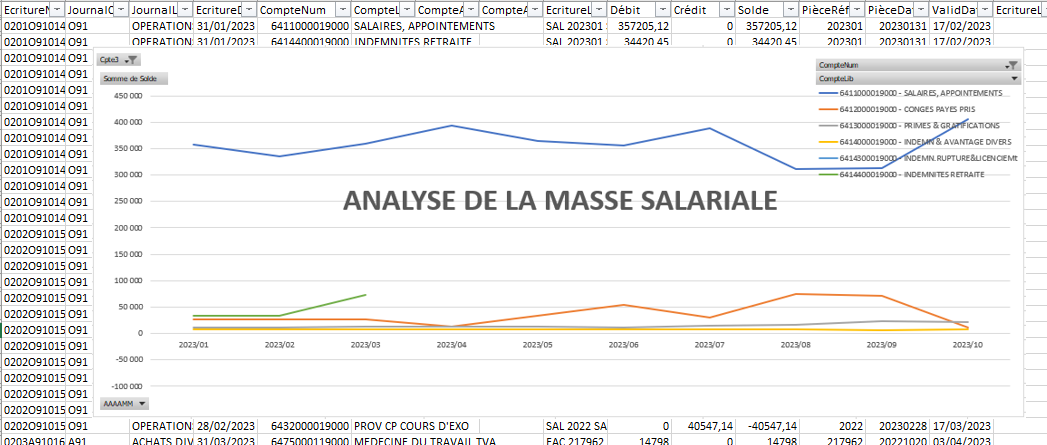
L’article qui suit sera illustré d’un exemple clef en main à titre de démonstration. Cet exemple est le script Python du programme FEC Augmenté.
Ce programme ajoute les champs suivants sur chaque ligne des FEC qui lui sont soumis :
- Solde (débit-crédit) ;
- MtTVA : compte identifié comme un compte de TVA ;
- BaseTVA : compte identifié comme une base TVA ;
- EcritureTxTVA : taux de TVA de l’écriture comptable (reporté sur chaque ligne de l’écriture) ;
- AAAAMM : champ date type 2023/12 ;
- Cpte1, Cpte2, Cpte3, Cpte4, Cpte5, Cpte6 : racines de compte.
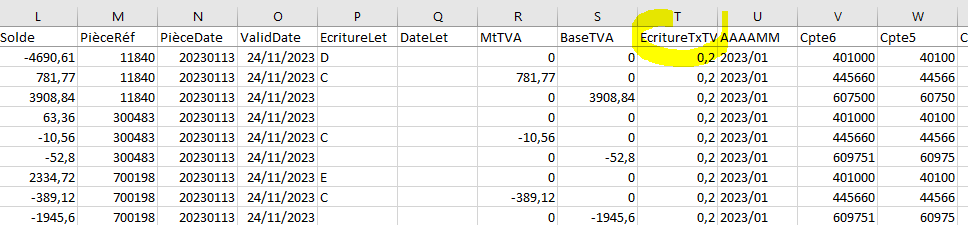
FEC augmenté = FEC + champs additionnels : taux de TVA, racines de compte, solde et mois (AAAA/MM)
Ces champs facilitent l’analyse des données comptables.
Exemples d’analyses permises avec ces nouveaux champs de données :
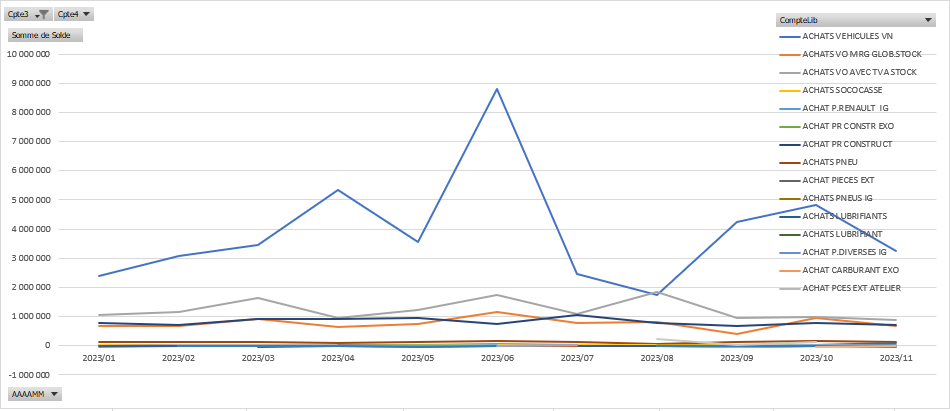
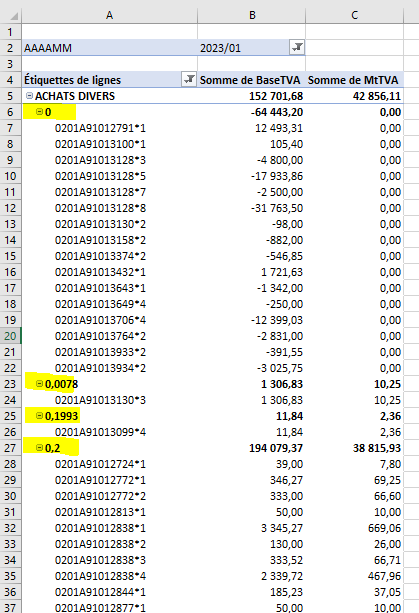
Le graphique croisé dynamique (GCD) réalisé dans Excel ci-après analyse les achats sur un exercice comptable :
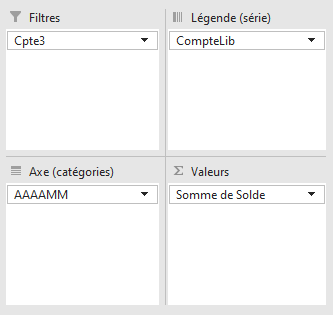
Disposition des champs de données pour obtenir ce GCD :
Le tableau croisé dynamique (TCD) suivant liste toutes les écritures comptables classées par journal comptable et par taux de TVA. Dans le cadre d’un audit de la TVA, l’utilisateur peut focaliser son attention sur des achats de location de véhicules de tourisme dont la TVA a été récupérée ou sur des ventes exonérées de TVA, voire sur des inversions HT/TVA…
Utilisation du programme FEC Augmenté :
Pour utiliser le programme FEC Augmenté, deux solutions :
- Soit charger le fichier FEC Augmenté.py (téléchargeable en pied d’article, à renommer de *.txt en *.py) dans l’interpréteur Python ;
- Soit double-cliquer sur le fichier FEC Augmenté.exe (contenu dans l’archive Zip téléchargeable en pied d’article) ; ne pas lancer l’exécution du programme à partir du Zip ; il faut préalablement le dézipper avant usage.
Le programme FEC Augmenté se présente ainsi :
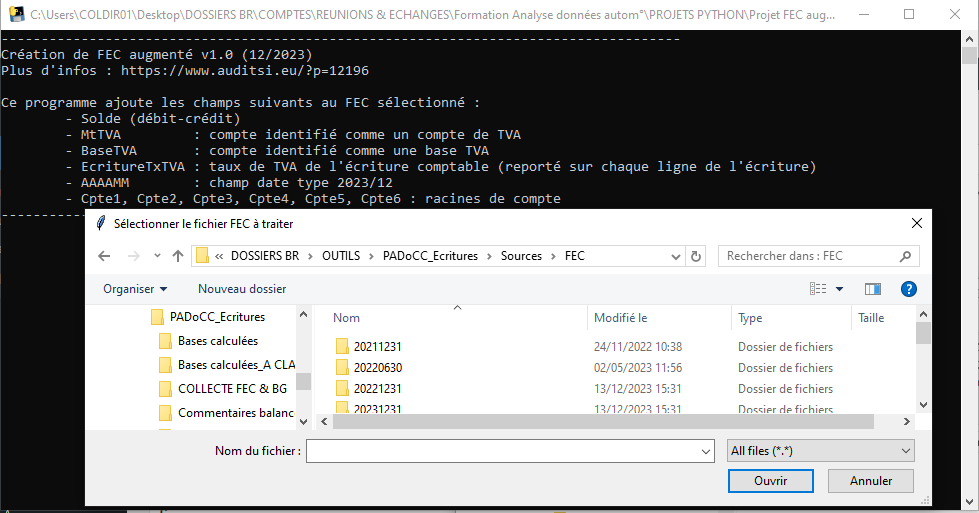
Le programme invite l’utilisateur à choisir un FEC.
Une fois le FEC sélectionné, cliquer sur Ouvrir. Après quelques instants, le FEC Augmenté est généré (sous la forme d’un fichier texte). Le temps de calcul dépend de la taille du FEC initial (généralement, d’après mes tests, de quelques secondes à quelques dizaines de secondes).
Le FEC augmenté est généré dans le dossier qui contient l’exécutable. Le FEC augmenté est enregistré sous le même format qu’un FEC réglementaire mais comprend plus de champs de donneées que les 18 ou 19 standard.
C’est tout simple, non ?
FEC Augmenté est fourni gracieusement à titre de démonstration, sans aucune garantie de bon fonctionnement.
Quelques explications sur le code-source du programme :
Ce script fait appel aux fonctions additionnelles proposées par les bibliothèques externes os (pour operating system : fonction de gestion de fichiers…), sys (pour interagir avec l’interpréteur Python), easygui (interface graphique utilisateur : fenêtres…), pandas (analyse et manipulation de données) :
# Importation des bibliothèques externes import os import sys import easygui import pandas as pd
Le programme affiche des messages d’introduction avec la commande print :
# Message d'introduction
print("-" * 85)
print("Création de FEC augmenté v1.0 (12/2023)")
print("Plus d'infos : https://www.auditsi.eu/?p=12196")
print()
print("Ce programme ajoute les champs suivants au FEC sélectionné :")
print(f"\t- Solde (débit-crédit)")
print(f"\t- MtTVA : compte identifié comme un compte de TVA")
print(f"\t- BaseTVA : compte identifié comme une base TVA")
print(f"\t- EcritureTxTVA : taux de TVA de l'écriture comptable (reporté sur chaque ligne de l'écriture)")
print(f"\t- AAAAMM : champ date type 2023/12")
print(f"\t- Cpte1, Cpte2, Cpte3, Cpte4, Cpte5, Cpte6 : racines de compte")
print("-" * 85)
print()
A noter :
- La chaîne \t permet d’insérer une tabulation.
- La commande print(“-” * 85) afficher une ligne constituée de 85 signes moins…
Ceci fait, la commande fileopenbox affiche une fenêtre demandant à l’utilisateur de sélectionner un FEC :
# Boîte de dialogue de sélection d'un fichier FEC fichier_FEC = easygui.fileopenbox(title="Sélectionner le fichier FEC à traiter", default=chemin_FEC, filetypes=["*.txt"])
Les paramètres de fileopenbox à fournir :
- Barre de titre de la fenêtre : title=”Sélectionner le fichier FEC à traiter” ;
- Chemin d’accès aux FEC ouvert par défaut : default=chemin_FEC (défini en amont par la commande os.getcwd(), c’est-à-dire le dossier où est enregistrée l’application FEC Augmenté) ;
- Type de fichier à afficher : *.txt : (filetypes=[“*.txt”])).
Une fois le fichier sélectionné par l’utilisateur, son nom est stocké dans la variable fichier_FEC.
Si l’utilisateur referme la fenêtre de sélection de fichier sans choisir de FEC (par exemple en appuyant sur le bouton Annuler ou la touche Echap), la variable fichier_FEC renverra un résultat nul. Bien entendu, dans ce cas il faut stopper l’exécution du script. C’est le rôle de ce code :
# Aucun FEC sélectionné (Echap ou Annuler)
if not fichier_FEC:
print("Aucun FEC sélectionné.")
sys.exit()
Le test conditionnel if not fichier_FEC: vérifie que la variable est vide et affiche un message et arrête le programme (sys.exit()).
Ensuite, le script cherche à identifier le séparateur de FEC :
# Identification du séparateur de champs de données
separateur=recherche_separateur(fichier_FEC)
if separateur=="E":
print("FEC non reconnu.")
sys.exit()
Le séparateur de champs est déterminé par la fonction recherche_separateur créée ici :
# Identification du séparateur de champs (tabulation ou pipe)
def recherche_separateur(fichier_FEC):
separateur=""
# Vérification si le fichier est un FEC
if os.path.isfile(fichier_FEC) and fichier_FEC.lower().endswith('.txt'):
try:
# Lecture de la première ligne du fichier pour obtenir le séparateur
with open(fichier_FEC, 'r') as f:
premiere_ligne = f.readline().strip()
# Séparateur tabulation (\t)
if premiere_ligne.startswith("JournalCode\tJournalLib"):
separateur="\t"
# Séparateur pipe (|)
elif premiere_ligne.startswith("JournalCode|JournalLib"):
separateur="|"
# Sinon Erreur (E)
else:
separateur="E"
return separateur
except Exception:
return "E"
Une fonction utilisateur est introduite par la commande def. Pour identifier le séparateur, cette fonction ouvre le FEC (open), lit la première ligne du FEC (readline…) et confronte (if… elif… else:) le début de la ligne lue (startswith) avec une chaîne prédéfinie (“JournalCode\tJournalLib” puis “JournalCode|JournalLib”). A partir du résultat obtenu, la fonction retourne le séparateur identifié ou “E” si aucun séparateur reconnu n’a pu être trouvé.
Pour mémoire, le CGI définit la tabulation et la pipe (|) comme seuls séparateurs régulièrement admis.
Une fois le séparateur identifié, le FEC est ouvert (à l’aide de la commande read_csv) :
# Chargement du FEC fec = pd.read_csv(fichier_FEC, delimiter=separateur, encoding='ISO-8859-1', dtype=str)
Ensuite, des champs de données sont ajoutés au FEC :
# Création du champ Solde = Debit - Credit
fec['Solde'] = fec['Debit'] - fec['Credit']
# Création du champ AAAAMM (AAAA/MM)
fec['AAAAMM'] = pd.to_datetime(fec['EcritureDate'], format='%d/%m/%Y').dt.strftime('%Y/%m')
# Création des champs MtTVA et BaseTVA à l'aide des fonctions ad hoc
fec['MtTVA'] = fec.apply(calcul_champ_mttva, axis=1)
fec['BaseTVA'] = fec.apply(calcul_champ_basetva, axis=1)
# Création des champs EcritureTxTVA (taux de TVA)
# --- Regroupement par EcritureNum et calcul de la somme de BaseTVA et MtTVA
regroupement_donnees = fec.groupby('EcritureNum')[['BaseTVA', 'MtTVA']].sum().reset_index()
# --- Pour chaque EcritureNum, calcul du Taux de TVA (si BaseTVA nulle, le résultat renvoyé est 'nan')
regroupement_donnees['EcritureTxTVA'] = regroupement_donnees['MtTVA'] / regroupement_donnees['BaseTVA']
# --- Fusion des résultats du regroupement dans le FEC d'origine en fonction de EcritureNum
fec = pd.merge(fec, regroupement_donnees[['EcritureNum', 'EcritureTxTVA']], on='EcritureNum', how='left')
# --- Champ EcritureTxTVA arrondi à quatre décimales
fec['EcritureTxTVA'] = fec['EcritureTxTVA'].round(4)
# Création des champs racine de compte Cpte1..Cpte6
fec['Cpte6'] = fec['CompteNum'].str[:6].astype(int)
fec['Cpte5'] = fec['CompteNum'].str[:5].astype(int)
fec['Cpte4'] = fec['CompteNum'].str[:4].astype(int)
fec['Cpte3'] = fec['CompteNum'].str[:3].astype(int)
fec['Cpte2'] = fec['CompteNum'].str[:2].astype(int)
fec['Cpte1'] = fec['CompteNum'].str[0].astype(int)
Le champ Solde résulte d’un calcul entre deux cahmps préexistants (Debit-Credit).
Le calcul de la base de TVA (BaseTVA) et du montant de la TVA (MtTVA) fait appel à deux fonctions créées ad hoc :
# Création du champ MtTVA
def calcul_champ_mttva(row):
if row['CompteNum'].startswith(('44562', '44566', '4457', '44586', '44587')):
return row['Solde']
return 0
# Création du champ BaseTVA
def calcul_champ_basetva(row):
if row['CompteNum'].startswith(('6', '7', '20', '21', '23')):
if not row['CompteNum'].startswith(('603', '68', '78')):
return row['Solde']
return 0
Pour le champ MtTVA, les comptes de TVA à retenir commencent par 44562x (TVA déductible sur immobilisations), 44566x (TVA déductible sur biens et services), 4457x (TVA collectée), 44586/7x (TVA sur comptes de coupures). Pour le champ BaseTVA, les bases de TVA sont formées par l’ensemble des comptes de charges et de produits (sauf comptes de variations de stock (603x), de dotations et de reprises de dépréciations (68/78x)), des comptes d’immobilisations incorporelles (20x), corporelles (21x) et en cours (23x).
Le calcul du champ EcritureTxTVA résulte de la division opérée entre MtTVA et BaseTVA. Pour calculer le taux de TVA au niveau de chaque écriture, il est nécessaire d’effectuer un regroupement (avec la commande groupby à la manière d’une requête regroupement SQL GROUP BY). Le taux de TVA est arrondi sur quatre décimales (round(4)). Par exemple : 0,2000 soit 20,00 %.
Enfin, le FEC agrémenté des changements ci-avant mentionnés est enregistré (to_csv) sous son nom d’origine prédécé du préfixe “FEC augmenté “ sauf si le fichier de destination existe déjà (os.path.isfile) auquel cas le programme s’arrête sans enregistrer les données.
# Récupération du nom du FEC sans l'arborescence
nom_FEC = os.path.basename(fichier_FEC)
# Création du nom de FEC augmenté
fichier_FEC_augmente = chemin_Appli + '\\' + "FEC augmenté " + nom_FEC
# Si le FEC existe déjà -> arrêt du programme
if os.path.isfile(fichier_FEC_augmente):
print(f"Le fichier {fichier_FEC_augmente} existe déjà. Traitement annulé")
sys.exit()
# Sinon : enregistrement du FEC modifié dans un nouveau fichier texte
else:
print(f"Le fichier {fichier_FEC_augmente} a été généré avec succès.")
fec.to_csv(fichier_FEC_augmente, sep=separateur, index=False, encoding='ISO-8859-1')
Code-source intégral du programme :
# -------------------------------------------------------------------------------------------
# Création de FEC augmenté
# v1.0 12/2023
# Plus d'infos : https://www.auditsi.eu/?p=12196
# -------------------------------------------------------------------------------------------
# Importation des bibliothèques externes
import os
import sys
import easygui
import pandas as pd
# Identification du séparateur de champs (tabulation ou pipe)
def recherche_separateur(fichier_FEC):
separateur=""
# Vérification si le fichier est un FEC
if os.path.isfile(fichier_FEC) and fichier_FEC.lower().endswith('.txt'):
try:
# Lecture de la première ligne du fichier pour obtenir le séparateur
with open(fichier_FEC, 'r') as f:
premiere_ligne = f.readline().strip()
# Séparateur tabulation (\t)
if premiere_ligne.startswith("JournalCode\tJournalLib"):
separateur="\t"
# Séparateur pipe (|)
elif premiere_ligne.startswith("JournalCode|JournalLib"):
separateur="|"
# Sinon Erreur (E)
else:
separateur="E"
return separateur
except Exception:
return "E"
# Création du champ MtTVA
def calcul_champ_mttva(row):
if row['CompteNum'].startswith(('44562', '44566', '4457', '44586', '44587')):
return row['Solde']
return 0
# Création du champ BaseTVA
def calcul_champ_basetva(row):
if row['CompteNum'].startswith(('6', '7', '20', '21', '23')):
if not row['CompteNum'].startswith(('603', '68', '78')):
return row['Solde']
return 0
# Message d'introduction
print("-" * 85)
print("Création de FEC augmenté v1.0 (12/2023)")
print("Plus d'infos : https://www.auditsi.eu/?p=12196")
print()
print("Ce programme ajoute les champs suivants au FEC sélectionné :")
print(f"\t- Solde (débit-crédit)")
print(f"\t- MtTVA : compte identifié comme un compte de TVA")
print(f"\t- BaseTVA : compte identifié comme une base TVA")
print(f"\t- EcritureTxTVA : taux de TVA de l'écriture comptable (reporté sur chaque ligne de l'écriture)")
print(f"\t- AAAAMM : champ date type 2023/12")
print(f"\t- Cpte1, Cpte2, Cpte3, Cpte4, Cpte5, Cpte6 : racines de compte")
print("-" * 85)
print()
# Chemin d'accès par défaut
chemin_Appli = os.getcwd()
chemin_FEC = chemin_Appli
# Boîte de dialogue de sélection d'un fichier FEC
fichier_FEC = easygui.fileopenbox(title="Sélectionner le fichier FEC à traiter", default=chemin_FEC, filetypes=["*.txt"])
# Aucun FEC sélectionné (Echap ou Annuler)
if not fichier_FEC:
print("Aucun FEC sélectionné.")
sys.exit()
# Identification du séparateur de champs de données
separateur=recherche_separateur(fichier_FEC)
if separateur=="E":
print("FEC non reconnu.")
sys.exit()
# Chargement du FEC
fec = pd.read_csv(fichier_FEC, delimiter=separateur, encoding='ISO-8859-1', dtype=str)
# Conversion des champs Debit et Credit en numérique (remplacement de la décimale , par un .)
fec['Debit'] = pd.to_numeric(fec['Debit'].str.replace(',', '.'), errors='coerce')
fec['Credit'] = pd.to_numeric(fec['Credit'].str.replace(',', '.'), errors='coerce')
# Création du champ Solde = Debit - Credit
fec['Solde'] = fec['Debit'] - fec['Credit']
# Conversion des champs EcritureDate, ValidDate et DateLet au format JJ/MM/AAAA
fec['EcritureDate'] = pd.to_datetime(fec['EcritureDate'], format='%Y%m%d').dt.strftime('%d/%m/%Y')
fec['ValidDate'] = pd.to_datetime(fec['ValidDate'], format='%Y%m%d').dt.strftime('%d/%m/%Y')
fec['DateLet'] = pd.to_datetime(fec['DateLet'], format='%Y%m%d').dt.strftime('%d/%m/%Y')
# Création du champ AAAAMM (AAAA/MM)
fec['AAAAMM'] = pd.to_datetime(fec['EcritureDate'], format='%d/%m/%Y').dt.strftime('%Y/%m')
# Création des champs MtTVA et BaseTVA à l'aide des fonctions ad hoc
fec['MtTVA'] = fec.apply(calcul_champ_mttva, axis=1)
fec['BaseTVA'] = fec.apply(calcul_champ_basetva, axis=1)
# Création des champs EcritureTxTVA (taux de TVA)
# --- Regroupement par EcritureNum et calcul de la somme de BaseTVA et MtTVA
regroupement_donnees = fec.groupby('EcritureNum')[['BaseTVA', 'MtTVA']].sum().reset_index()
# --- Pour chaque EcritureNum, calcul du Taux de TVA (si BaseTVA nulle, le résultat renvoyé est 'nan')
regroupement_donnees['EcritureTxTVA'] = regroupement_donnees['MtTVA'] / regroupement_donnees['BaseTVA']
# --- Fusion des résultats du regroupement dans le FEC d'origine en fonction de EcritureNum
fec = pd.merge(fec, regroupement_donnees[['EcritureNum', 'EcritureTxTVA']], on='EcritureNum', how='left')
# --- Champ EcritureTxTVA arrondi à quatre décimales
fec['EcritureTxTVA'] = fec['EcritureTxTVA'].round(4)
# Création des champs racine de compte Cpte1..Cpte6
fec['Cpte6'] = fec['CompteNum'].str[:6].astype(int)
fec['Cpte5'] = fec['CompteNum'].str[:5].astype(int)
fec['Cpte4'] = fec['CompteNum'].str[:4].astype(int)
fec['Cpte3'] = fec['CompteNum'].str[:3].astype(int)
fec['Cpte2'] = fec['CompteNum'].str[:2].astype(int)
fec['Cpte1'] = fec['CompteNum'].str[0].astype(int)
# Remplacement des points par des virgules dans les champs de montant (Debit, Credit, Solde, BaseTVA, MtTVA, TxTVA...)
fec[['Debit', 'Credit', 'Solde', 'MtTVA', 'BaseTVA', 'EcritureTxTVA']] = fec[['Debit', 'Credit', 'Solde', 'MtTVA', 'BaseTVA', 'EcritureTxTVA']].apply(lambda x: x.astype(str).str.replace('.', ','))
# Renommage des champs CompAuxNum et CompAuxLib en CompteAuxNum et CompteAuxLib
fec.rename(columns={'CompAuxNum': 'CompteAuxNum', 'CompAuxLib': 'CompteAuxLib', 'Debit': 'Débit', 'Credit': 'Crédit', 'PieceRef': 'PièceRéf', 'PieceDate': 'PièceDate'}, inplace=True)
# Modification de l'ordre des champs de données
columns_order = ['EcritureNum', 'JournalCode', 'JournalLib', 'EcritureDate', 'CompteNum', 'CompteLib', 'CompteAuxNum', 'CompteAuxLib', 'EcritureLib', 'Débit', 'Crédit', 'Solde', 'PièceRéf', 'PièceDate', 'ValidDate', 'EcritureLet', 'DateLet', 'MtTVA', 'BaseTVA', 'EcritureTxTVA', 'AAAAMM', 'Cpte6', 'Cpte5', 'Cpte4', 'Cpte3', 'Cpte2', 'Cpte1']
# --- Si le champ CodeEtabt existe, le mettre en dernier
if 'CodeEtabt' in fec.columns:
columns_order.remove('CodeEtabt')
columns_order.append('CodeEtabt')
# --- Mise en oeuvre de l'ordre indiqué
fec = fec[columns_order]
# Récupération du nom du FEC sans l'arborescence
nom_FEC = os.path.basename(fichier_FEC)
# Création du nom de FEC augmenté
fichier_FEC_augmente = chemin_Appli + '\\' + "FEC augmenté " + nom_FEC
# Si le FEC existe déjà -> arrêt du programme
if os.path.isfile(fichier_FEC_augmente):
print(f"Le fichier {fichier_FEC_augmente} existe déjà. Traitement annulé")
sys.exit()
# Sinon : enregistrement du FEC modifié dans un nouveau fichier texte
else:
print(f"Le fichier {fichier_FEC_augmente} a été généré avec succès.")
fec.to_csv(fichier_FEC_augmente, sep=separateur, index=False, encoding='ISO-8859-1')
# Message final
print()
print("Traitement terminé.")
Autre exemple de script Python : calcul d’échéancier d’emprunt.
___
Pour approfondir le sujet : se former à la programmation en langage Python pour automatiser ses tâches


Derniers articles parBenoît RIVIERE (voir tous)
- Clôture comptable : optimiser l’existant pour mieux automatiser demain - dimanche 19 juillet 2026
- Quand un simple “œ” entraîne le rejet d’une liasse fiscale - mercredi 13 mai 2026
- Affiner le cadrage de la TVA avec ANA-FEC 2 - samedi 28 février 2026
- Comprendre l’hameçonnage en 30 secondes - samedi 21 février 2026
- Révision des comptes : justifier rapidement un compte non lettré avec Excel - dimanche 8 février 2026
C’est un très bon fichier qui facilite l’analyse, je te félicite.
Merci de partager si possible
Pingback: Clôtures comptables : Testez vos FEC avant de les archiver... - Audit & Systèmes d'Information
Pingback: Révisez les comptes d'une entreprise à partir de son FEC - Audit & Systèmes d'Information