
La révision des comptes d’un groupe se confronte généralement à la disponibilité des données comptables disséminées sur de nombreux systèmes.
Cette difficulté peut être résolue de diverses manières. Un simple module d’extraction de données peut parfaitement faire l’affaire. Grâce à quelques lignes de Python, il est aisé de centraliser les données à auditer dans un fichier texte ou un classeur Excel.
A titre d’illustration, voici l’esquisse d’un module d’extraction d’écritures comptables, pour le moment expérimental. Ce script Python d’à peine cent lignes extrait les lignes d’écritures comptables de l’ensemble des entités d’un groupe selon les critères définis dans une requête SQL puis exporte le résultat obtenu dans un fichier texte et un classeur Excel. Rudimentaire mais parfaitement opérationnel… et surtout gains de temps assurés. Ce module s’inscrit dans la continuité du projet PADoCC_Ecritures (supervision des opérations comptables d’un groupe).
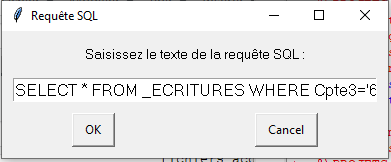
Une fois l’exécution du script lancée, une fenêtre attend que l’utilisateur saisisse une requête SQL (commande enterbox de la bibliothèque easygui) :
Quelques exemples de requêtes SQL :
Requête programmée par défaut dans le script (stockée dans la variable requete_sql) :
SELECT * FROM _ECRITURES WHERE Cpte3='613'
Cette requête liste toutes les lignes d’écritures comptables dont le compte général commence par 613x (comptes de locations).
Pour restreindre ces lignes aux seules écritures d’achat (donc hors écritures de bilan ou de situation : CCA, FNP…) :
SELECT * FROM _ECRITURES WHERE Cpte3='613' AND TypeJournal='ACHATS'
Pour encore affiner l’extraction aux seuls achats de location soumis à la TVA au taux normal (20 % : CodeTVA=’TN’) :
SELECT * FROM _ECRITURES WHERE Cpte3='613' AND TypeJournal='ACHATS' AND CodeTVA='TN'
Ce genre de requêtes s’avère utile par exemple pour identifier les locations de véhicules dont la TVA a fait l’objet d’une récupération. Il s’agit ici de s’assurer que la TVA sur location de véhicules de tourisme n’a pas été récupérée indûment sur le Trésor.
Une autre façon d’obtenir le même résultat est de passer par le schéma d’écriture. Cette requête liste toutes les lignes d’écriture d’achat de location (613x) qui ont fait l’objet d’une récupération de TVA (SchémEcrit_Nature =‘ACHATS_a/TVA_6HA’) :
SELECT * FROM _ECRITURES WHERE Cpte3='613' AND SchémEcrit_Nature =‘ACHATS_a/TVA_6HA’
Autre exemple : pour extraire le chiffre d’affaires HT exonéré de TVA en fonction du schéma d’écriture comptable, la requête SQL pourra être libellée sous cette forme (les écritures de ventes exonérées de TVA sont codifiée sous le libellé de schéma suivant : SchémEcrit_Nature =’VENTES_ssTVA_700x’) :
SELECT * FROM _ECRITURES WHERE Cpte2='70' AND SchémEcrit_Nature ='VENTES_ssTVA_700x'
Les écritures de ventes sans TVA doivent faire l’objet d’une justification (exportations, livraisons intracommunautaires, ventes de déchets, ventes de biens d’occasion…).
>>> Plus d’informations sur l’analyse des schémas d’écritures : cf l’article Analyse des schémas d’écriture.
>>> Pour découvrir le langage de requêtes SQL, lire la série d’articles sur l’analyse de données.

Une fois la requête validée par l’utilisateur, le programme Python l’exécute sur l’ensemble des bases de données comptables du groupe.
Le coeur du module Python : une boucle for… in… qui exécute la requête de l’utilisateur (df = pd.read_sql(requete_sql, conn)) sur chacune des bases de données comptables. Le résultat de la requête, stocké dans la variable df (pour Data Frame), est ensuite concaténé avec le résultat des autres entités du groupe (df_concat = pd.concat([df_concat, df], ignore_index=True)). Les bibliothèques pyodbc et pandas fournissent respectivement les fonctions de connexion à la source de données et de gestion des données.
for fichier_accdb in fichiers_accdb:
bdd_en_cours = os.path.join(chemin_dossier, fichier_accdb)
print(f"Base en cours : {bdd_en_cours}")
try:
connection_str = f"DRIVER={{Microsoft Access Driver (*.mdb, *.accdb)}};DBQ={bdd_en_cours};"
conn = pyodbc.connect(connection_str)
cursor = conn.cursor()
# Liste des tables de la BDD
tables = [table.table_name for table in cursor.tables(tableType='TABLE')]
# Nom de la table à vérifier
nom_table = "_ECRITURES"
# Vérifie si la table existe
if '_ECRITURES' in tables:
df = pd.read_sql(requete_sql, conn)
# Ajout du résultats au DataFrame global
df_concat = pd.concat([df_concat, df], ignore_index=True)
else:
print(f"Ignoré : {nom_table} n'est pas présente dans la base de données {bdd_en_cours}.")
cursor.close()
conn.close()
except pyodbc.Error as e:
print(f"Erreur lors de la récupération des données dans {bdd_en_cours}: {e}")
Une fois toutes les bases de données comptables passées en revue, le module d’extraction génère un fichier texte et un classeur Excel (bibliothèque de fonctions openpyxl) reprenant l’ensemble des lignes d’écritures correspondant aux critères définis par la requête (clause SQL WHERE).
Ecran du requêteur une fois les extractions Excel et texte terminées…
___
Pour approfondir le sujet : se former à la programmation en langage Python pour automatiser ses tâches
Derniers articles parBenoît RIVIERE (voir tous)
- Clôture comptable : optimiser l’existant pour mieux automatiser demain - dimanche 19 juillet 2026
- Quand un simple “œ” entraîne le rejet d’une liasse fiscale - mercredi 13 mai 2026
- Affiner le cadrage de la TVA avec ANA-FEC 2 - samedi 28 février 2026
- Comprendre l’hameçonnage en 30 secondes - samedi 21 février 2026
- Révision des comptes : justifier rapidement un compte non lettré avec Excel - dimanche 8 février 2026